Private Search and AI Answers for Your Data
Kavunka — Statistical Search Engine
Kavunka is a private search engine for indexing websites, documents, and internal knowledge bases.
Kavunka Search is a unique product and a practical alternative to Elasticsearch for teams that need private, controllable search on their own infrastructure.
It uses transparent statistical ranking instead of opaque semantic matching, making results easier to inspect, tune, and reproduce.
Kavunka can index both web pages and PDF documents, giving AI agents and users a reliable searchable knowledge base.
Kavunka — search driven by data mathematics.
Kavunka is a private search engine for indexing websites, documents, and internal knowledge bases.
Kavunka Search is a unique product and a practical alternative to Elasticsearch for teams that need private, controllable search on their own infrastructure.
It uses transparent statistical ranking instead of opaque semantic matching, making results easier to inspect, tune, and reproduce.
Kavunka can index both web pages and PDF documents, giving AI agents and users a reliable searchable knowledge base.
Kavunka — search driven by data mathematics.
iFigure — Retrieval-Based AI Agent
iFigure is an AI agent that answers questions using information retrieved by Kavunka.
It runs multiple structured searches, combines ranked evidence, and keeps answers grounded in your data.
If relevant information is missing, iFigure says “I don’t know.” If the answer cannot be produced with enough confidence, it says “I am not confident in my answer.”
iFigure — precision through controlled retrieval.
iFigure is an AI agent that answers questions using information retrieved by Kavunka.
It runs multiple structured searches, combines ranked evidence, and keeps answers grounded in your data.
If relevant information is missing, iFigure says “I don’t know.” If the answer cannot be produced with enough confidence, it says “I am not confident in my answer.”
iFigure — precision through controlled retrieval.
Run it on your infrastructure
Want to try Kavunka and iFigure on your own data? Request a demo and we can deploy the software on your server for free, connect the first data source, and walk you through the first working search.

Kavunka is a high-performance, multi-threaded search engine designed for large-scale web crawling and data extraction. It supports automatic language detection for web pages, currently including English, German, Italian, French, Portuguese, Spanish, Polish, Ukrainian, and Russian.
Kavunka corrects user query errors to ensure high-quality search results and retrieves large text segments from web pages, making it particularly effective for Retrieval-Augmented Generation (RAG) applications. Its crawling infrastructure supports JavaScript-rendered pages and configurable request handling, enabling comprehensive and efficient data collection.
How can this be used?
1.
Use Kavunka and iFigure to add an advanced, reliable help system to your website. Kavunka indexes your site, and iFigure answers from that indexed content, helping reduce unsupported responses and unnecessary external links. Your users get fast, accurate, context-specific information directly from your site.
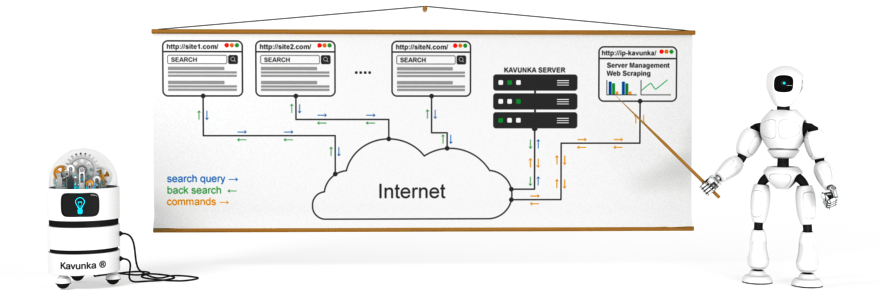
2. You can also use software for scraping a large number of web pages. Kavunka can use go-rod. Crawling by Chrome allows you to receive data from JavaScript Websites. After crawling the site, you can receive a scraping report in any format: json, csv, xml.

3. Site owners can use Kavunka to build topic-specific search services and attract more useful traffic. You can manually select sources by subject, such as games, cars, real estate, or medicine, then configure parsers to extract structured data like prices, ratings, and reviews.
After indexing, Kavunka can present this information in a convenient search interface on your own site. Users get a richer SERP and can search relevant external content without leaving your resource.
After indexing, Kavunka can present this information in a convenient search interface on your own site. Users get a richer SERP and can search relevant external content without leaving your resource.

Examples
| Website | Subject of sites | Language | Hardware |
|---|---|---|---|
| Kavunka.com | Internal search on the site | EN | VPS |
| Kavunka.net (You need to request a demo) |
Search engine demonstrating the capabilities of the Kavunka engine & iFigure AI Agent (access on request) | EN | Intel Xeon 32-core, 196GB RAM, RTX 3090 24GB |
Screenshots
×
❮
❯
![]()