How to Scrape Walmart Product Pricing, Data and Images
Walmart Inc. it is an American retail corporation. There are about 34 million pages in Google
search Walmart.com. These are mainly consumer goods. From the pages of this site you can get: product description,
image, price, reviews, etc. In this tutorial, I'll show you how to quickly and easily set up Walmart.com web
scraping and get a huge amount of data about products in a specific category.
To extract data from this site, we need a proxy, configured selenium and the Kavunka search engine. We will receive
the following data:
- NAME - product name;
- BRAND - manufacturer's brand;
- IMAG - image;
- PRICE - price;
- RATING - rating;
- DESCR - product description;
- CREV - Customer reviews;
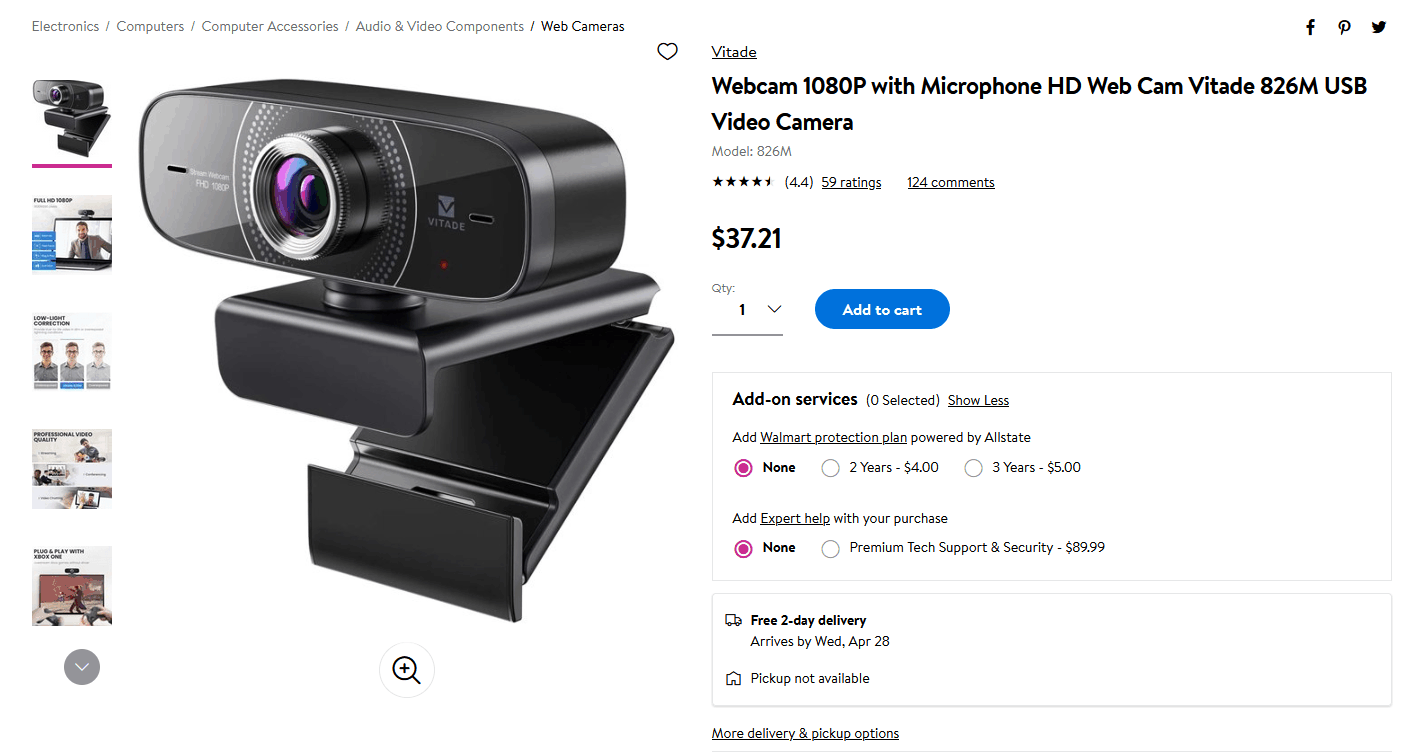
Let's take a look at the html-code of this page (Ctrl + A followed by the left mouse button and View Selection
Source). It may seem that the browser is frozen, but that's okay you need to wait a bit. Now let's find the name of
the webcam "Webcam 1080P with Microphone HD Web Cam Vitade 826M USB Video Camera". The product name is in many
places, but I found a JSON string that contains our webcam and other information.
 This is luck - it will be much easier for us to get data from this site now. Let's go to the search engine admin
panel in the "TESTER" tab and use the "Regular expressions designer". Next, fill in the fields as shown in the image.
This is luck - it will be much easier for us to get data from this site now. Let's go to the search engine admin
panel in the "TESTER" tab and use the "Regular expressions designer". Next, fill in the fields as shown in the image.
Regular expressions
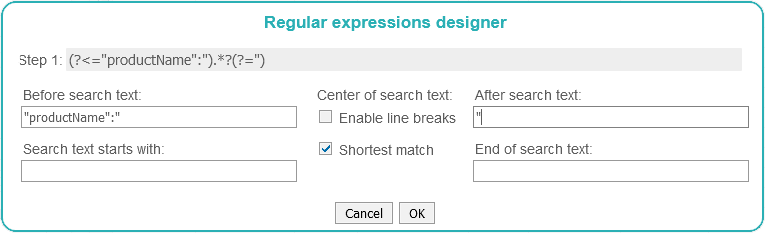
As a result, we got a regular expression for NAME
Step 1:
For the rest of the fields, we do the same. As a result, we get such regular expressions. Using regular expressions step by step allows you to do Walmart scraping quickly and accurately.
BRAND
Step 1:
IMAG
Step 1:
PRICE
Step 1:
RATING
Step 1:
DESCR
Step 1:
CREV
Step 1:
Step 1:
(?<="productName":").*?(?=")
For the rest of the fields, we do the same. As a result, we get such regular expressions. Using regular expressions step by step allows you to do Walmart scraping quickly and accurately.
BRAND
Step 1:
(?<=class="prod\-brandName)[\w\W]*?(?=</a><h1)
IMAG
Step 1:
(?<=<meta\ property="og:image"\ content=")[\w\W]*?(?=")
PRICE
Step 1:
(?<=itemprop="price"\ content=").*?(?=")
RATING
Step 1:
(?<=itemprop="price"\ content=").*?(?=")
DESCR
Step 1:
(?<=<div\ class="about\-desc)[\w\W]*?(?=</div)
CREV
Step 1:
(?<=<div\ class="review\-text">)[\w\W]*?(?=</div>)
Scan Settings
Using Selenium: Yes
Delay (sec.): 3
Parse Everything: No
Min. "gf": 7 (gf – the number of filled fields, if the gf parameter is lower than the specified one, then the page will not be saved)
User-Agent: (this field is filled in automatically)
Priority Anchors: Webcam, Video Camera, Web Cam (if the crawler comes across a link that contains these words, then the link will be crawled first).
Priority URLs: /ip/ (if the url contains these signs, then it will be scanned first).
Save the template and go to the "TASKS" tab then add the task for Octopus, Worder and KAVUNKA (reload). After the scan is complete, we download the data from the walmart.com website (the DATA button in the "SITES" tab)
Delay (sec.): 3
Parse Everything: No
Min. "gf": 7 (gf – the number of filled fields, if the gf parameter is lower than the specified one, then the page will not be saved)
User-Agent: (this field is filled in automatically)
Priority Anchors: Webcam, Video Camera, Web Cam (if the crawler comes across a link that contains these words, then the link will be crawled first).
Priority URLs: /ip/ (if the url contains these signs, then it will be scanned first).
Save the template and go to the "TASKS" tab then add the task for Octopus, Worder and KAVUNKA (reload). After the scan is complete, we download the data from the walmart.com website (the DATA button in the "SITES" tab)