How to Scrape Amazon for free
In this tutorial, I will teach you how to get product data from Amazon. Before parsing any site, you need to check what data we will receive if we make a request using
curl. Why is this necessary:
As a result, we got an html page with the <title> caption "Sorry! Something went wrong!" It looks like we can't do without JavaScript Rendering.
- using JavaScript Rendering significantly reduces the scanning speed;
- this is an additional load on the server;
- scanning will be performed in one thread.
curl -A " Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:80.0) Gecko/20100101 Firefox/80.0"
https://www.amazon.com/TP-Link-AC1750-Smart-WiFi-Router/dp/B079JD7F7G/
As a result, we got an html page with the <title> caption "Sorry! Something went wrong!" It looks like we can't do without JavaScript Rendering.
What is JavaScript Rendering?
JavaScript is a programming language for manipulating elements of a web page, that is,
scripts written in JavaScript can load data into objects from third-party sources using AJAX. Rendering is
displaying, drawing, displaying information in the browser. Thus, JavaScript Rendering allows you to get a
full-fledged html-code of a page with a text description of the product and its photos.
In order to successfully receive data from Amazon, we need to use a browser that will process
JavaScript scripts. A big question arises before us. How to make browser (Firefox, Chrome or Opera) work
automatically? There is the Selenium WebDriver technology for this. If you
want to use the Kavunka search engine for scraping, then the installation of
Selenium WebDriver and the Firefox browser occurs during the deployment of the search engine on the server.
Now let's take a look at the fields that we will be parsing in this example:
Now let's take a look at the fields that we will be parsing in this example:
- NAME - product name
- BRAND - brand name
- CAT - the category to which the product belongs
- CATURL - Url address of the category
- IMG - main picture of the product
- AIMGS - additional pictures
- PRICE - price
- RATING - rating (stars)
- DSCR - Product Description
Next, for each field, we need to create regular expressions. To create and test regular
expressions online, you can on this page or go to the TESTER tab in the control panel of the Kavunka search engine.
For quick creation of regular expressions we will use "Regular expressions designer". Press  and we get a dialog box with fields that need to be filled in.
and we get a dialog box with fields that need to be filled in.
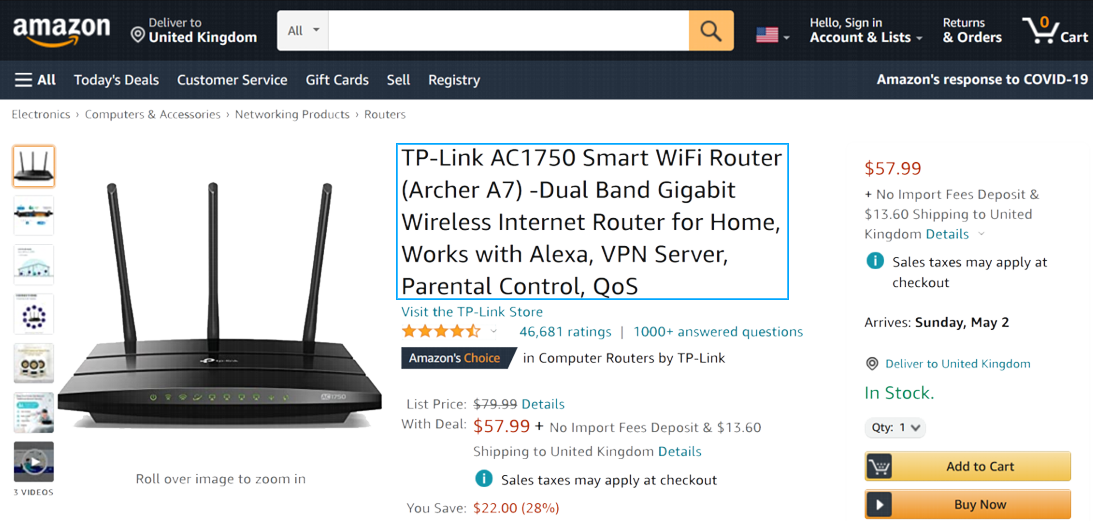
Let's start with NAME (product name). In the browser, we can see that the product is called "TP-Link AC1750 Smart WiFi Router (Archer A7) -Dual Band Gigabit Wireless Internet Router for Home, Works with Alexa, VPN Server, Parental Control, QoS".
Let's start with NAME (product name). In the browser, we can see that the product is called "TP-Link AC1750 Smart WiFi Router (Archer A7) -Dual Band Gigabit Wireless Internet Router for Home, Works with Alexa, VPN Server, Parental Control, QoS".
Press Ctrl + A in the browser, left mouse button, "View Selection Source". Why did
we select the text, and then choose "View Selection Source", after all, you could have just looked at the source code ofthe page?
In order for JavaScript Rendering to work and provide us with the full html-code of the page. Then press Ctrl + F
and find the name of our product in the code.
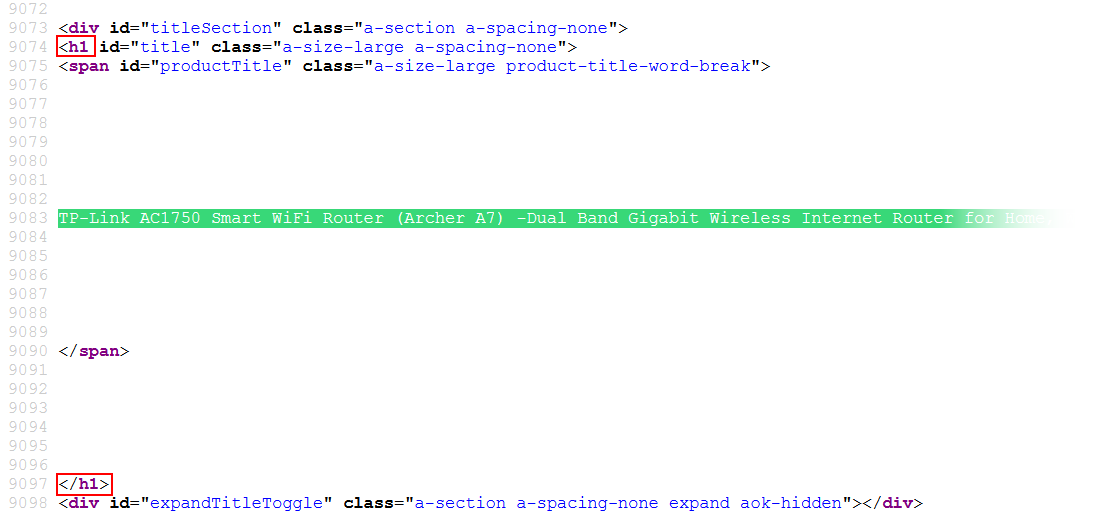
As we can see, the text we need is between the <h1 and </h1> tags. Return
to the template editing page and fill in the "Before search text" and "After search text" fields, check "Enable line
breaks" and "Shortest match", click OK. As a result, we got a regular expression:
(?<=<h1)[\w\W]*?(?=<\/h1>)
We do the same for the rest of the fields
BRAND
Step 1:
CAT
Step 1:
CATURL
Step 1:
IMG
Step 1:
AIMGS
Step 1:
PRICE
Step 1:
DSCR
Step 1:
Step 1:
(?<=Brand</span>)[\w\W]*?(?=<\/span>)
It is worth noting that not all fields can be retrieved using a single regular expression. There are steps
for this. At the first step, we get a part of the html-code, to which we apply the regular expressions from Step
2. If we still failed to get the text we need at the second step, then we use Step 3.
CAT
Step 1:
(?<=<li\ class="a\-breadcrumb\-divider">)[\w\W]*?(?=<\/ul>)
Step 2:
(?<=<li><span\ class="a\-list\-item">)
CATURL
Step 1:
(?<=<li\ class="a\-breadcrumb\-divider">)[\w\W]*?(?=<\/ul>)
Step 2:(?<=<li><span\ class="a\-list\-item">)[\w\W]*?(?=<\/a>)
Step 3:(?<=href=").*?(?=")
IMG
Step 1:
(?<='colorImages':).*(?=\}\,)
Step 2:
(?<="large":").*?(?=")
AIMGS
Step 1:
(?<="main":).*?(?=\,"variant":)
Step 2:(?<=").*?(?=":)
On different Amazon pages, the price of an item is in different places. Then we create two variants of the regular
expression and put the "or" sign between them.
PRICE
Step 1:
(?<=?<span\ id="priceblock_ourprice").*?(?=?<\/span>)|(?<=id="priceblock_dealprice").*?(?=?<\/span>)
DSCR
Step 1:
(?<=<div\ id="productDescription")[\w\W]*?(?=<style)
Step 2:(?<=<p>)[\w\W]*?(?=<\/p>)
Scan Settings
- Using Selenium Yes/No (use or not use Selenium, choose "Yes")
- Delay (sec.) 3 (the browser needs a delay in order for it to execute all JavaScript scripts and give us the full html-code)
- Parse Everything Yes/No (here we leave "No" this will allow us not to save pages with non-unique text)
- Min. "gf" 8 (the number of fields that could be obtained, if the crawler did not receive a sufficient number of good fields, it will ignore this page)
- Priority Anchors (if the crawler comes across links with certain anchors, it will mark them as priority)
- Priority URLs (this is similar to "Priority Anchors", but here the crawler is looking at parts of the urls)
- URL Filtering (in order not to waste the crawler's time crawling unnecessary pages, we can indicate the signs of these pages)
Crawling and Parsing
Save the template and go to the "TASKS" tab. Add a task for Octopus (specify the start page, select the template we
created, and indicate how many pages the crawler should visit). Add a task for Worder and Kavunka, press "Start" and
go drink tea with cookies.
Getting Hot DATA
After a pleasant tea, we return to "WEBSITES", find amazon.com, then click "DATA" and get the data. I want to note
that Amazon is quite democratic about parsing! I managed to get over 2000 pages without using Proxy :). Using the
Kavunka software you can get huge amounts of data on Amazon products for free.